This post originally appeared on the engineering blog of Babylon.
# Abstract
Babylon’s reliance on GitOps as an operational and change release framework led to a high (and at times abusive) usage of the GitHub API. Frequent rate-limiting and lack of observability in terms of which client, workflow, and team is abusing the API resulted in a suboptimal developer experience. The GitHub-Proxy is a minimal, in-house solution that enables Babylon to consume the GitHub API efficiently at scale.
# A brief history of GitOps at Babylon
At Babylon, the vast majority of our deployment interfaces relies on GitOps. From releasing a new version of a Kubernetes microservice to changing the instance type of a PostgreSQL database, Babylon engineers interact with multiple GitOps repositories - either directly or through automated CD workflows. Over the years, these GitOps repositories have evolved to support more than 400 microservices that are owned by a range of ~60 teams. Scaling our GitOps workflows to such an extent has come with a variety of interesting challenges. Keeping the workflows performant is crucial for a delightful developer experience. Additionally, since they modify products and services that impact the clinical safety of our patients, these workflows must meet an exceptionally high bar in terms of compliance, security, and reliability.
To achieve such scale, we had to come up with an ecosystem of tooling that improves all aspects of the GitOps life cycle. This tooling ranges from small OSS utilities - such as danger.js, which helps with automating code review chores - to advanced in-house tools - such as Autodoc, which generates the release documentation required by our auditors. These programs are primarily executed as independent processes within the CI or CD workflows of our repositories, and as one would expect, integrate heavily with the APIs of our Git vendor, GitHub.
# The problem
Since all of our GitOps repositories are private, we had to figure out a method that would enable each of these processes to authenticate against the GitHub API. When setting up the workflows originally, we naively decided to stick with the simplest option of using personal access tokens (PATs). We created a bot user account, stored its PAT at the top level config of each workflow and voilà - the job processes now had direct access to private resources sitting behind the GitHub API.
This sort of access model has served us well for quite some time. However, over the past few years the organization went through massive growth and so did the number of its microservices, yielding a textbook demonstration of Conway’s Law. The rate of deployment that our GitOps workflows needed to withstand had drastically increased. It was no later than early 2021 when we started observing sporadic failures of our CI/CD jobs, due to the GitHub API returning unexpected 403s. Apparently, the bot GitHub user was being rate-limited for short time intervals. The problem only became worse in the months to follow, with the bot user at times exhausting the entire 5000 requests per hour limit in less than 30 minutes, leaving the workflows blocked for the remainder of the one-hour window (after which the counter refreshes). This bot user had become a single point of failure - a buggy CI check introduced by one team would end up blocking the workflows of all other teams. During these internal rate-limiting outages, teams were not able to make new releases, nor roll back erroneous ones. Everyone was agonizingly waiting for the rate-limit counter to reset, which was uncool to say the least.
Note: The API rate-limit quotas cannot be increased by upgrading the account plan. The rate limit serves purely as an anti-abuse safeguard.
To top it off, there was very little observability in terms of which job was abusing the API. Unfortunately, GitHub has no built-in dashboard that visualizes such metrics. We had to poll the Rate Limit API ourselves through a long-running thread which would then expose the polled metrics for Prometheus to collect. This basic monitoring gave us some insight on the total usage of the bot user account. However, since all jobs were using tokens originating from that same user, it was still not possible to identify the culprit. It became apparent that more granular monitoring was needed.
As the rate-limiting became more frequent, we started discouraging engineers from using the existing bot user tokens when developing new jobs or workflows. Soon, engineers would create their own GitHub apps (or bot users) and request to have them installed on our org. Installing a new app requires organization owner privileges, which have only been granted to a small group of highly trusted individuals. This high bus factor provided our engineers with yet another bottleneck, as requests for new app installations started queuing up in the backlog of the DevEx team.
# The solution
In the beginning of 2022, it was evident that we had to come up with a proper solution to the problem.
It was time to address the following areas of concern (in order by severity):
- Performance degradation and/or blocking of CI/CD.
- High coupling between the different workflows that interact with the GitHub API. A rate-limiting failure would cascade across all workflows that use the same bot user.
- Lack of observability in terms of which workflows are consuming the API and at what rate.
- Revoking & rotating GitHub credentials across our GitOps estate.
- High bus factor when it comes to provisioning new GitHub apps or bot users
From a non-functional angle, the solution needed to be performant, highly available, and cater for the increase in usage rates that we expect in the coming years.
It is important to note that the rate-limiting was only imposed on interactions with the GitHub HTTP APIs (REST and GraphQL). Git operations were not problematic.
Initially, we considered scaling the existing model vertically, which essentially meant replacing the bot user with a single org-wide GitHub app. GitHub apps are subject to a higher rate limit of 15,000 requests per hour (3× higher than regular users). This option was rejected as it would only push the problem a few months down the road.
An alternative would be to scale the existing model horizontally. Rather than having a single global GitHub integration (user or app), we could allocate one integration (GitHub app) per workflow. Each workflow would then be given a rate limit of 15k RPH, at the expense of doing an extra network call to authenticate itself as an App installation and obtain an access token. Although this option addressed both the rate-limiting and observability dimensions of the problem, it was rejected due to the following cons:
- Incompatibility with our existing workflow implementations. We would need to modify all workflow steps to cater for the initial authentication step.
- It is not trivial to persist an obtained access token across jobs of the same workflow. This results in redundant network calls for app authentication.
- Does not reduce the high bus factor in provisioning new GitHub apps.
GitHub’s REST API implements the HTTP concept of conditional requests which do not count against the rate limit. Unfortunately, utilizing such requests from within our workflows was pointless, since these workflows are traditionally implemented as collections of job processes that run independently to each other. This arrangement does not really allow hot resources (and their Etags) to be shared across different workflows - or even jobs of the same workflow.
Although conditional requesting was not something we could use directly in our existing setup, it pointed us towards the direction of caching. We started contemplating on whether a caching proxy that sits between our workflows and the GitHub servers would do the trick. Perhaps someone else may have already thought about this before us. In fact, both Google and Sourcegraph have adopted a similar proxy pattern to enhance other aspects of the GitHub API. In particular, Google’s magic GitHub API proxy provides IAM for GitHub API tokens, and Sourcegraph’s GitHub proxy offers improved monitoring of rate-limit metrics.
Following a 2-day proof of concept exercise, it was clear to the team that the caching proxy solution could work. We decided to go full steam ahead and build our very own GitHub proxy: a caching forward proxy to GitHub’s REST and GraphQL APIs.
Babylon’s GitHub proxy consists of a Kubernetes microservice and a Redis cluster hosted in one of our AWS environments. It listens for HTTP requests that match any path and proxies them verbatim to the GitHub host. The GitHub API response - containing the Etag header - is then stored in Redis and returned to the client (see the relevant sequence diagrams). The proxy essentially provides a centralized store of Etags that can be shared and re-used amongst its client base, letting workflows take full advantage of conditional requests. Additionally, the proxy emits rich telemetry data, exposing the client usage and rate-limit consumption metrics for our Prometheus instance to collect.
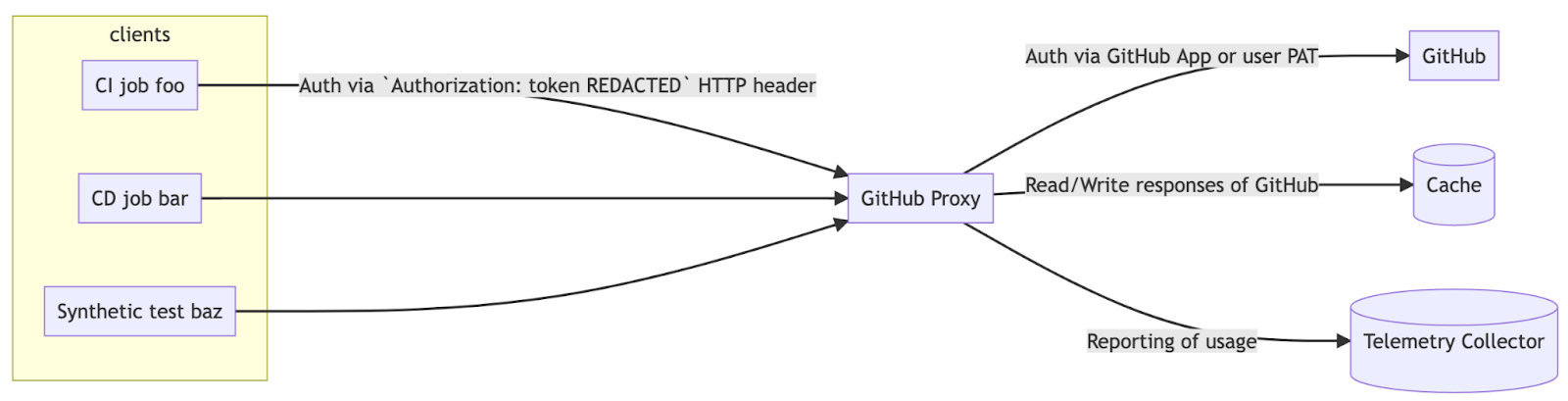
The proxy authenticates with GitHub using an internal, extensible pool of GitHub credentials (either GitHub Apps or user PATs), enabling the automatic rotation of rate-limited tokens. This central pool of credentials negates the need for managing a GitHub app or bot user account per client.
Each of the clients is handed its own proxy token to authenticate against the proxy. This token can be used in place of a GitHub PAT, which allows clients to use the proxy as if it was a regular GitHub Enterprise server. From a client’s perspective, the proxy is 100% compatible with GitHub’s REST and GraphQL APIs.
The proxy itself provides a client registry where engineers of Babylon can add new clients or modify existing ones, without the need to liaise with the DevEx team. A client may also be configured to only have access to a restricted set of API resource scopes.
Example of a simplified client registry:
---
version: 1
clients:
- name: test
token: H+hYxlecgRq7yfmhq2COlJk7tpSwDmdsp8thdPsnbnQ=
- name: read_only
token: oed4+Uo4s4mgwstjSAY/N+HSOsGwfbX91QxqSOjsVlU=
scopes:
- method: GET
path: .*Using the above client registry, the proxy annotates request metrics with the corresponding client name, enabling high granularity monitoring.
From the ground up, we developed the core of the proxy to be a Babylon agnostic python framework, based on Werkzeug (and good intentions 😉). It is a thin, highly configurable, highly extensible framework offering out-of-the-box support for Flask and Redis. Note that the proxy can be extended to integrate with other application frameworks, databases, and monitoring tools.
We are delighted to announce that our github-proxy is now open source and will soon be available to install through PyPI.
# The results
The proxy was rolled out to production in an incremental manner, migrating one workflow at a time. Due to the PAT compatibility of the proxy, migrating a workflow was only a matter of pointing it from the GitHub host (api.github.com) to the proxy host and replacing the PAT of the bot user with a proxy token.
As soon as the first proxy metrics arrived at the panels of our Grafana dashboard, we knew that this tool would be a breakthrough in the way we do GitOps.
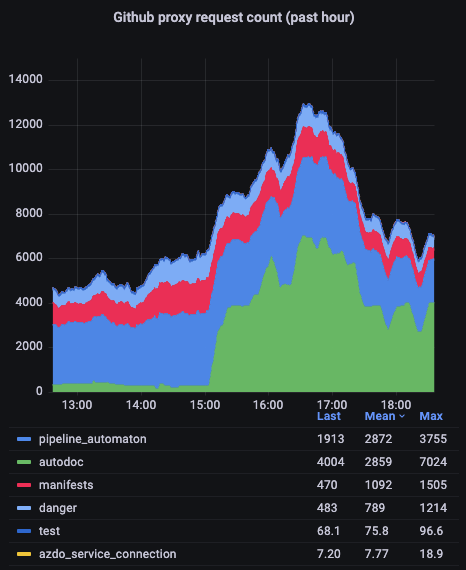
The panel visualizing the GitHub API usage of each client provided us with instant feedback on potential candidates that might be abusing the API.
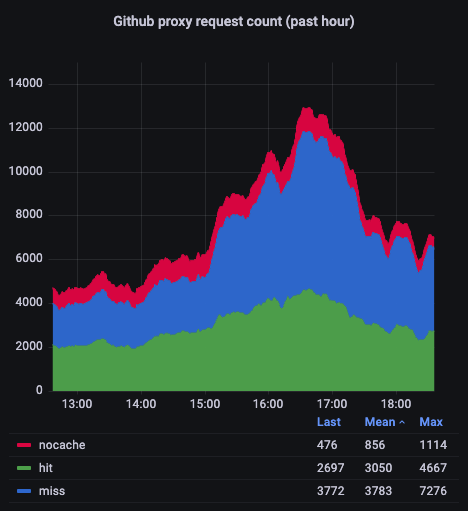
Another panel helped us assess the performance of the proxy’s cache. The plot below shows that ~40% (!!!) of our GitHub API interactions are being served by the cache without consuming additional rate-limit credits.
Besides the usage of clients, we visualized the rate-limit metrics of each GitHub credential from the pool that the proxy uses to authenticate against GitHub. For the time being, the pool contains just a single GitHub app credential, which proved to be adequate, given the outstanding performance of the cache.
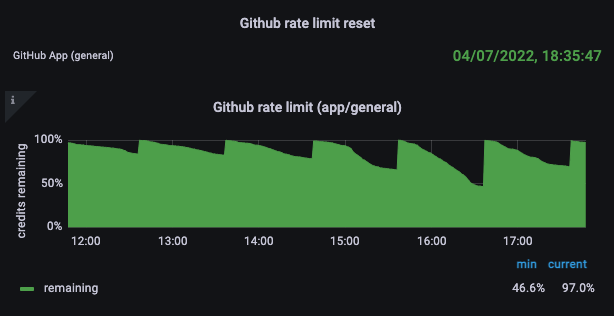
However, our favorite panel is the one visualizing the number of rate limiting outages that our engineers would experience if the original setup of the bot user account was still in place.
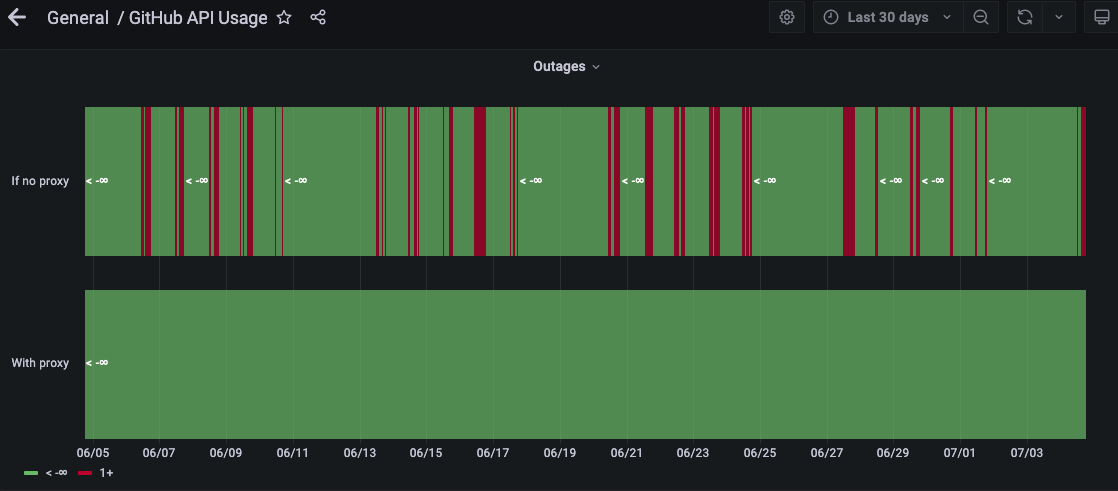
The proxy has now been running in production for a little over 3 months, serving up to ~500 requests per minute and improving the developer experience of our engineers.
It is important to highlight that the proxy is not the final piece in the puzzle. Becoming more resilient to the misuse of the GitHub API was an evil necessity rather than a key objective. The lack of internal outages does not negate the fact that a number of hidden workflow jobs are still abusing the API. With the help of the proxy though, we can now track down these jobs and engage with the respective owner teams. There are also plans to place proactive alerting on top of the existing Prometheus metrics so that our engineers can catch potential issues upfront, without any coordination from the DevEx team, and before an incident even occurs.
